The Lagrangian method for extracting perfect squares is an example. Reducing a quadratic form to canonical form
Reduction of quadratic forms
Let us consider the simplest and most often used in practice method of reducing a quadratic form to canonical form, called Lagrange method. It is based on isolating a complete square in quadratic form.
Theorem 10.1(Lagrange's theorem). Any quadratic form (10.1):
using a non-special linear transformation (10.4) can be reduced to the canonical form (10.6):
 ,
,
□ We will prove the theorem in a constructive way using Lagrange's method of extracting perfect squares. The task is to find a non-singular matrix such that the linear transformation (10.4) results in a quadratic form (10.6) of canonical form. This matrix will be obtained gradually as the product of a finite number of matrices of a special type.
Point 1 (preparatory).
1.1. Let us select among the variables one that is included in the quadratic form squared and to the first power at the same time (let’s call it leading variable). Let's move on to point 2.
1.2. If there are no leading variables in the quadratic form (for all : ), then we select a pair of variables whose product is included in the form with a non-zero coefficient and move on to step 3.
1.3. If in a quadratic form there are no products of opposite variables, then this quadratic form is already represented in canonical form (10.6). The proof of the theorem is complete.
Point 2 (selecting a complete square).
2.1. Using the leading variable, we select a complete square. Without loss of generality, assume that the leading variable is . Grouping the terms containing , we get
 .
.
Selecting a perfect square by variable in ![]() , we get
, we get
 .
.
Thus, as a result of isolating the complete square with a variable, we obtain the sum of the square of the linear form
which includes the leading variable, and quadratic form ![]() from variables , in which the leading variable is no longer included. Let's make a change of variables (introduce new variables)
from variables , in which the leading variable is no longer included. Let's make a change of variables (introduce new variables)


we get a matrix

() non-singular linear transformation, as a result of which the quadratic form (10.1) will take next view
With quadratic form ![]() Let's do the same as in point 1.
Let's do the same as in point 1.
2.1. If the leading variable is the variable , then you can do it in two ways: either select a complete square for this variable, or perform renaming (renumbering) variables:
with a non-singular transformation matrix:
 .
.
Point 3 (creating a leading variable). We replace the selected pair of variables with the sum and difference of two new variables, and replace the remaining old variables with the corresponding new variables. If, for example, in paragraph 1 the term was highlighted
then the corresponding change of variables has the form
and in quadratic form (10.1) the leading variable will be obtained.
For example, in the case of changing variables:
the matrix of this non-singular linear transformation has the form
 .
.
As a result of the above algorithm (sequential application of points 1, 2, 3), the quadratic form (10.1) will be reduced to the canonical form (10.6).
Note that as a result of the transformations performed on the quadratic form (selecting a complete square, renaming and creating a leading variable), we used elementary non-singular matrices of three types (they are matrices of transition from basis to basis). The required matrix of the non-singular linear transformation (10.4), under which the form (10.1) has the canonical form (10.6), is obtained by multiplying a finite number of elementary non-singular matrices of three types. ■
Example 10.2. Give quadratic form
to canonical form by the Lagrange method. Indicate the corresponding non-singular linear transformation. Perform check.
Solution. Let's choose the leading variable (coefficient). Grouping the terms containing , and selecting a complete square from it, we obtain
where indicated
Let's make a change of variables (introduce new variables)

Expressing the old variables in terms of the new ones:

we get a matrix

Definition 10.4.Canonical view quadratic form (10.1) is called the following form: . (10.4)
Let us show that in a basis of eigenvectors, the quadratic form (10.1) takes on a canonical form. Let
 - normalized eigenvectors corresponding to eigenvalues λ 1 ,λ 2 ,λ 3 matrices (10.3) in an orthonormal basis. Then the transition matrix from the old basis to the new one will be the matrix
- normalized eigenvectors corresponding to eigenvalues λ 1 ,λ 2 ,λ 3 matrices (10.3) in an orthonormal basis. Then the transition matrix from the old basis to the new one will be the matrix
 . In the new basis the matrix A will accept diagonal view(9.7) (by the property of eigenvectors). Thus, transforming the coordinates using the formulas:
. In the new basis the matrix A will accept diagonal view(9.7) (by the property of eigenvectors). Thus, transforming the coordinates using the formulas:
 ,
,
in the new basis we obtain the canonical form of a quadratic form with coefficients equal to the eigenvalues λ 1, λ 2, λ 3:
Remark 1. From a geometric point of view, the considered coordinate transformation is a rotation of the coordinate system, combining the old coordinate axes with the new ones.
Remark 2. If any eigenvalues of the matrix (10.3) coincide, we can add a unit vector orthogonal to each of them to the corresponding orthonormal eigenvectors, and thus construct a basis in which the quadratic form takes the canonical form.
Let us bring the quadratic form to canonical form
x² + 5 y² + z² + 2 xy + 6xz + 2yz.
Its matrix has the form In the example discussed in Lecture 9, the eigenvalues and orthonormal eigenvectors of this matrix are found:
![]()
![]() Let's create a transition matrix to the basis from these vectors:
Let's create a transition matrix to the basis from these vectors:
 (the order of the vectors is changed so that they form a right-handed triple). Let's transform the coordinates using the formulas:
(the order of the vectors is changed so that they form a right-handed triple). Let's transform the coordinates using the formulas:
 .
.

So, the quadratic form is reduced to canonical form with coefficients equal to the eigenvalues of the matrix of the quadratic form.
Lecture 11.
Second order curves. Ellipse, hyperbola and parabola, their properties and canonical equations. Reducing a second order equation to canonical form.
Definition 11.1.Second order curves on a plane are called the lines of intersection of a circular cone with planes that do not pass through its vertex.
If such a plane intersects all the generatrices of one cavity of the cone, then in the section it turns out ellipse, at the intersection of the generatrices of both cavities – hyperbola, and if the cutting plane is parallel to any generatrix, then the section of the cone is parabola.
Comment. All second-order curves are specified by second-degree equations in two variables.
Ellipse.
Definition 11.2.Ellipse is the set of points in the plane for which the sum of the distances to two fixed points is F 1 and F tricks, is a constant value.
Comment. When the points coincide F 1 and F 2 the ellipse turns into a circle.
Let us derive the equation of the ellipse by choosing the Cartesian system
y M(x,y) coordinates so that the axis Oh coincided with a straight line F 1 F 2, beginning
r 1 r 2 coordinates – with the middle of the segment F 1 F 2. Let the length of this
segment is equal to 2 With, then in the chosen coordinate system
F 1 O F 2 x F 1 (-c, 0), F 2 (c, 0). Let the point M(x, y) lies on the ellipse, and
the sum of the distances from it to F 1 and F 2 equals 2 A.
Then r 1 + r 2 = 2a, But ,
therefore, introducing the notation b² = a²- c² and after carrying out simple algebraic transformations, we obtain canonical ellipse equation: (11.1)
Definition 11.3.Eccentricity of an ellipse is called the magnitude e=s/a (11.2)
Definition 11.4.Headmistress D i ellipse corresponding to the focus F i F i relative to the axis OU perpendicular to the axis Oh on distance a/e from the origin.
Comment. With a different choice of coordinate system, the ellipse can be specified not by the canonical equation (11.1), but by a second-degree equation of a different type.
Ellipse properties:
1) An ellipse has two mutual perpendicular to the axis symmetry (the main axes of the ellipse) and the center of symmetry (the center of the ellipse). If an ellipse is given by a canonical equation, then its main axes are the coordinate axes, and its center is the origin. Since the lengths of the segments formed by the intersection of the ellipse with the main axes are equal to 2 A and 2 b (2a>2b), then the main axis passing through the foci is called the major axis of the ellipse, and the second main axis is called the minor axis.
2) The entire ellipse is contained within the rectangle
3) Ellipse eccentricity e< 1.
Really,
4) The directrixes of the ellipse are located outside the ellipse (since the distance from the center of the ellipse to the directrix is a/e, A e<1, следовательно, a/e>a, and the entire ellipse lies in a rectangle)
5) Distance ratio r i from ellipse point to focus F i to the distance d i from this point to the directrix corresponding to the focus is equal to the eccentricity of the ellipse.
Proof.
Distances from point M(x, y) up to the foci of the ellipse can be represented as follows:
Let's create the directrix equations:
(D 1), (D 2). Then ![]() From here r i / d i = e, which was what needed to be proven.
From here r i / d i = e, which was what needed to be proven.
Hyperbola.
Definition 11.5.Hyperbole is the set of points in the plane for which the modulus of the difference in distances to two fixed points is F 1 and F 2 of this plane, called tricks, is a constant value.
Let us derive the canonical equation of a hyperbola by analogy with the derivation of the equation of an ellipse, using the same notation.
|r 1 - r 2 | = 2a, from where If we denote b² = c² - a², from here you can get
- canonical hyperbola equation. (11.3)
Definition 11.6.Eccentricity a hyperbola is called a quantity e = c/a.
Definition 11.7.Headmistress D i hyperbola corresponding to the focus F i, is called a straight line located in the same half-plane with F i relative to the axis OU perpendicular to the axis Oh on distance a/e from the origin.
Properties of a hyperbola:
1) A hyperbola has two axes of symmetry (the main axes of the hyperbola) and a center of symmetry (the center of the hyperbola). In this case, one of these axes intersects with the hyperbola at two points, called the vertices of the hyperbola. It is called the real axis of the hyperbola (axis Oh for the canonical choice of the coordinate system). The other axis has no common points with the hyperbola and is called its imaginary axis (in canonical coordinates - the axis OU). On both sides of it are the right and left branches of the hyperbola. The foci of a hyperbola are located on its real axis.
2) The branches of the hyperbola have two asymptotes, determined by the equations
3) Along with hyperbola (11.3), we can consider the so-called conjugate hyperbola, defined by the canonical equation
for which the real and imaginary axis are swapped while maintaining the same asymptotes.
4) Eccentricity of the hyperbola e> 1.
5) Distance ratio r i from hyperbola point to focus F i to the distance d i from this point to the directrix corresponding to the focus is equal to the eccentricity of the hyperbola.
The proof can be carried out in the same way as for the ellipse.
Parabola.
Definition 11.8.Parabola is the set of points on the plane for which the distance to some fixed point is F this plane is equal to the distance to some fixed straight line. Dot F called focus parabolas, and the straight line is its headmistress.
To derive the parabola equation, we choose the Cartesian
coordinate system so that its origin is the middle
D M(x,y) perpendicular FD, omitted from focus on the directive
r su, and the coordinate axes were located parallel and
perpendicular to the director. Let the length of the segment FD
D O F x is equal to R. Then from the equality r = d follows that
![]() because the
because the
![]() Using algebraic transformations, this equation can be reduced to the form: y² = 2 px, (11.4)
Using algebraic transformations, this equation can be reduced to the form: y² = 2 px, (11.4)
called canonical parabola equation. Magnitude R called parameter parabolas.
Properties of a parabola:
1) A parabola has an axis of symmetry (parabola axis). The point where the parabola intersects the axis is called the vertex of the parabola. If a parabola is given by a canonical equation, then its axis is the axis Oh, and the vertex is the origin of coordinates.
2) The entire parabola is located in the right half-plane of the plane Ooh.
Comment. Using the properties of the directrixes of an ellipse and a hyperbola and the definition of a parabola, we can prove the following statement:
The set of points on the plane for which the relation e the distance to some fixed point to the distance to some straight line is a constant value, it is an ellipse (with e<1), гиперболу (при e>1) or parabola (with e=1).
Related information.
220400 Algebra and geometry Tolstikov A.V.
Lectures 16. Bilinear and quadratic forms.
Plan
1. Bilinear form and its properties.
2. Quadratic shape. Matrix of quadratic form. Coordinate transformation.
3. Reducing the quadratic form to canonical form. Lagrange method.
4. Law of inertia of quadratic forms.
5. Reducing the quadratic form to canonical form using the eigenvalue method.
6. Silverst’s criterion for the positive definiteness of a quadratic form.
1. Course of analytical geometry and linear algebra. M.: Nauka, 1984.
2. Bugrov Ya.S., Nikolsky S.M. Elements of linear algebra and analytical geometry. 1997.
3. Voevodin V.V. Linear algebra.. M.: Nauka 1980.
4. Collection of problems for colleges. Linear Algebra and Fundamentals mathematical analysis. Ed. Efimova A.V., Demidovich B.P.. M.: Nauka, 1981.
5. Butuzov V.F., Krutitskaya N.Ch., Shishkin A.A. Linear algebra in questions and problems. M.: Fizmatlit, 2001.
, , , ,
1. Bilinear form and its properties. Let V - n-dimensional vector space over the field P.
Definition 1.Bilinear form, defined on V, such a mapping is called g: V 2 ® P, which to each ordered pair ( x , y ) vectors x , y from puts in V match the number from the field P, denoted g(x , y ), and linear in each of the variables x , y , i.e. having properties:
1) ("x , y , z Î V)g(x + y , z ) = g(x , z ) + g(y , z );
2) ("x , y Î V) ("a О P)g(a x , y ) = a g(x , y );
3) ("x , y , z Î V)g(x , y + z ) = g(x , y ) + g(x , z );
4) ("x , y Î V) ("a О P)g(x ,a y ) = a g(x , y ).
Example 1. Any scalar product, defined on a vector space V is a bilinear form.
2 . Function h(x , y ) = 2x 1 y 1 - x 2 y 2 +x 2 y 1 where x = (x 1 ,x 2), y = (y 1 ,y 2)О R 2, bilinear form on R 2 .
Definition 2. Let v = (v 1 , v 2 ,…, v n V.Matrix bilinear form g(x , y ) relative to the basisv called a matrix B=(b ij)n ´ n, the elements of which are calculated by the formula b ij = g(v i, v j):
Example 3. Bilinear Matrix h(x , y ) (see example 2) relative to the basis e 1 = (1,0), e 2 = (0,1) is equal to .
Theorem 1. LetX, Y - coordinate columns of vectors respectivelyx , y in the basisv, B - matrix of bilinear formg(x , y ) relative to the basisv. Then the bilinear form can be written as
g(x , y )=X t BY. (1)
Proof. From the properties of the bilinear form we obtain
Example 3. Bilinear form h(x
,
y
) (see example 2) can be written in the form h(x
, y
)= .
.
Theorem 2. Let v = (v 1 , v 2 ,…, v n), u = (u 1 , u 2 ,…, u n) - two vector space basesV, T - transition matrix from the basisv to basisu. Let B= (b ij)n ´ n And WITH=(with ij)n ´ n - bilinear matricesg(x , y ) respectively relative to the basesv andu. Then
WITH=T t BT.(2)
Proof. By definition of the transition matrix and the bilinear form matrix, we find:

Definition 2. Bilinear form g(x , y ) is called symmetrical, If g(x , y ) = g(y , x ) for any x , y Î V.
Theorem 3. Bilinear formg(x , y )- symmetric if and only if a matrix of bilinear form is symmetric with respect to any basis.
Proof. Let v = (v 1 , v 2 ,…, v n) - basis of vector space V,B= (b ij)n ´ n- matrices of bilinear form g(x , y ) relative to the basis v. Let the bilinear form g(x , y ) - symmetrical. Then by definition 2 for any i, j = 1, 2,…, n we have b ij = g(v i, v j) = g(v j, v i) = b ji. Then the matrix B- symmetrical.
Conversely, let the matrix B- symmetrical. Then Bt= B and for any vectors x = x 1 v 1 + …+ x n v n =vX, y = y 1 v 1 + y 2 v 2 +…+ y n v n =vY Î V, according to formula (1), we obtain (we take into account that the number is a matrix of order 1, and does not change during transposition)
g(x , y ) =g(x , y )t = (X t BY)t = Y t B t X = g(y , x ).
2. Quadratic shape. Matrix of quadratic form. Coordinate transformation.
Definition 1.Quadratic shape defined on V, called mapping f:V® P, which for any vector x from V is determined by equality f(x ) = g(x , x ), Where g(x , y ) is a symmetric bilinear form defined on V .
Property 1.According to a given quadratic formf(x )the bilinear form is found uniquely by the formula
g(x , y ) = 1/2(f(x + y ) - f(x )-f(y )). (1)
Proof. For any vectors x , y Î V we obtain from the properties of the bilinear form
f(x + y ) = g(x + y , x + y ) = g(x , x + y ) + g(y , x + y ) = g(x , x ) + g(x , y ) + g(y , x ) + g(y , y ) = f(x ) + 2g(x , y ) + f(y ).
From this follows formula (1).
Definition 2.Matrix of quadratic formf(x ) relative to the basisv = (v 1 , v 2 ,…, v n) is the matrix of the corresponding symmetric bilinear form g(x , y ) relative to the basis v.
Theorem 1. LetX= (x 1 ,x 2 ,…, x n)t- coordinate column of the vectorx in the basisv, B - matrix of quadratic formf(x ) relative to the basisv. Then the quadratic formf(x )
Given a quadratic form (2) A(x, x) = , where x = (x 1 , x 2 , …, x n). Consider a quadratic form in space R 3, that is x = (x 1 ,
x 2 ,
x 3),
A(x,
x) =  +
+  +
+  +
+ 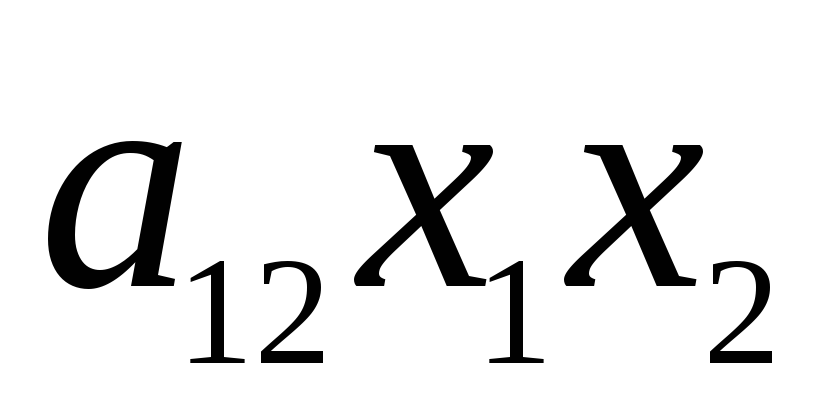 +
+  +
+  +
+
+
+  +
+  +
+  =
=  +
+  +
+  + 2
+ 2 + 2
+ 2 +
+ 2
+
+ 2 (we used the condition of shape symmetry, namely A 12 = A 21 ,
A 13 = A 31 ,
A 23 = A 32). Let's write out a matrix of quadratic form A in basis ( e},
A(e) =
(we used the condition of shape symmetry, namely A 12 = A 21 ,
A 13 = A 31 ,
A 23 = A 32). Let's write out a matrix of quadratic form A in basis ( e},
A(e) =  . When the basis changes, the matrix of quadratic form changes according to the formula A(f) = C t A(e)C, Where C– transition matrix from the basis ( e) to basis ( f), A C t– transposed matrix C.
. When the basis changes, the matrix of quadratic form changes according to the formula A(f) = C t A(e)C, Where C– transition matrix from the basis ( e) to basis ( f), A C t– transposed matrix C.
Definition11.12. The form of a quadratic form with a diagonal matrix is called canonical.
So let A(f) =  , Then A"(x,
x) =
, Then A"(x,
x) =  +
+  +
+  , Where x" 1 ,
x" 2 ,
x" 3 – vector coordinates x in a new basis ( f}.
, Where x" 1 ,
x" 2 ,
x" 3 – vector coordinates x in a new basis ( f}.
Definition11.13. Let in n V such a basis is chosen f = {f 1 , f 2 , …, f n), in which the quadratic form has the form
A(x, x) =  +
+  + … +
+ … +  ,
(3)
,
(3)
Where y 1 , y 2 , …, y n– vector coordinates x in basis ( f). Expression (3) is called canonical view quadratic form. Coefficients 1, λ 2, …, λ n are called canonical; a basis in which a quadratic form has a canonical form is called canonical basis.
Comment. If the quadratic form A(x, x) is reduced to canonical form, then, generally speaking, not all coefficients i are different from zero. The rank of a quadratic form is equal to the rank of its matrix in any basis.
Let the rank of the quadratic form A(x, x) is equal r, Where r ≤ n. A matrix of quadratic form in canonical form has a diagonal form. A(f) =  , since its rank is equal r, then among the coefficients i there must be r, not equal to zero. It follows that the number of nonzero canonical coefficients is equal to the rank of the quadratic form.
, since its rank is equal r, then among the coefficients i there must be r, not equal to zero. It follows that the number of nonzero canonical coefficients is equal to the rank of the quadratic form.
Comment. A linear transformation of coordinates is a transition from variables x 1 , x 2 , …, x n to variables y 1 , y 2 , …, y n, in which old variables are expressed through new variables with some numerical coefficients.
x 1 = α 11 y 1 + α 12 y 2 + … + α 1 n y n ,
x 2 = α 2 1 y 1 + α 2 2 y 2 + … + α 2 n y n ,
………………………………
x 1 = α n 1 y 1 + α n 2 y 2 + … + α nn y n .
Since each basis transformation corresponds to a non-degenerate linear coordinate transformation, the question of reducing a quadratic form to a canonical form can be solved by choosing the corresponding non-degenerate coordinate transformation.
Theorem 11.2 (main theorem about quadratic forms). Any quadratic form A(x, x), specified in n-dimensional vector space V, using a non-degenerate linear coordinate transformation can be reduced to canonical form.
Proof. (Lagrange method) The idea of this method is to sequentially complement the quadratic trinomial for each variable to a complete square. We will assume that A(x, x) ≠ 0 and in the basis e = {e 1 , e 2 , …, e n) has the form (2):
A(x,
x) =  .
.
If A(x, x) = 0, then ( a ij) = 0, that is, the form is already canonical. Formula A(x, x) can be transformed so that the coefficient a 11 ≠ 0. If a 11 = 0, then the coefficient of the square of another variable is different from zero, then by renumbering the variables it is possible to ensure that a 11 ≠ 0. Renumbering of variables is a non-degenerate linear transformation. If all the coefficients of the squared variables are equal to zero, then the necessary transformations are obtained as follows. Let, for example, a 12 ≠ 0 (A(x, x) ≠ 0, so at least one coefficient a ij≠ 0). Consider the transformation
x 1 = y 1 – y 2 ,
x 2 = y 1 + y 2 ,
x i = y i, at i = 3, 4, …, n.
This transformation is non-degenerate, since the determinant of its matrix is non-zero  =
=  = 2 ≠ 0.
= 2 ≠ 0.
Then 2 a 12 x 1 x 2 = 2
a 12 (y 1 – y 2)(y 1 + y 2) = 2 – 2
– 2 , that is, in the form A(x,
x) squares of two variables will appear at once.
, that is, in the form A(x,
x) squares of two variables will appear at once.
A(x,
x) =
 + 2
+ 2 + 2
+ 2 +
+  . (4)
. (4)
Let's convert the allocated amount to the form:
A(x,
x) = a 11  , (5)
, (5)
while the coefficients a ij change to  . Consider the non-degenerate transformation
. Consider the non-degenerate transformation
y 1 = x 1 +  + … +
+ … +  ,
,
y 2 = x 2 ,
y n = x n .
Then we get
A(x,
x) =  .
(6).
.
(6).
If the quadratic form  = 0, then the question of casting A(x, x) to canonical form is resolved.
= 0, then the question of casting A(x, x) to canonical form is resolved.
If this form is not equal to zero, then we repeat the reasoning, considering coordinate transformations y 2 , …, y n and without changing the coordinate y 1 . It is obvious that these transformations will be non-degenerate. In a finite number of steps, the quadratic form A(x, x) will be reduced to canonical form (3).
Comment 1. The required transformation of the original coordinates x 1 , x 2 , …, x n can be obtained by multiplying the non-degenerate transformations found in the process of reasoning: [ x] = A[y], [y] = B[z], [z] = C[t], Then [ x] = AB[z] = ABC[t], that is [ x] = M[t], Where M = ABC.
Comment 2. Let A(x,
x) = A(x, x) =  +
+ + …+
+ …+  , where i ≠ 0,
i = 1,
2, …, r, and 1 > 0, λ 2 > 0, …, λ q > 0,
λ q +1 < 0,
…, λ r < 0.
, where i ≠ 0,
i = 1,
2, …, r, and 1 > 0, λ 2 > 0, …, λ q > 0,
λ q +1 < 0,
…, λ r < 0.
Consider the non-degenerate transformation
y 1 =  z 1 ,
y 2 =
z 1 ,
y 2 =  z 2 ,
…, y q =
z 2 ,
…, y q =  z q ,
y q +1 =
z q ,
y q +1 =  z q +1 ,
…, y r =
z q +1 ,
…, y r =  z r ,
y r +1 = z r +1 ,
…, y n = z n. As a result A(x,
x) will take the form: A(x, x) =
z r ,
y r +1 = z r +1 ,
…, y n = z n. As a result A(x,
x) will take the form: A(x, x) =  +
+  + … +
+ … +  –
– 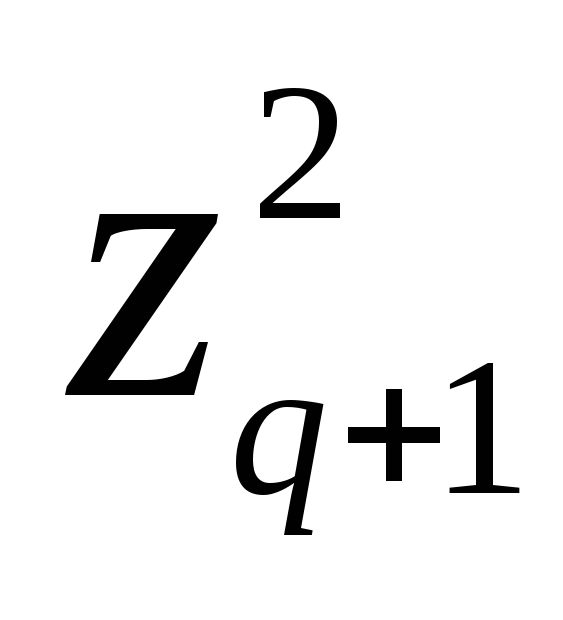 – … –
– … –  which is called normal form of quadratic form.
which is called normal form of quadratic form.
Example11.1. Reduce the quadratic form to canonical form A(x, x) = 2x 1 x 2 – 6x 2 x 3 + 2x 3 x 1 .
Solution. Because the a 11 = 0, use the transformation
x 1 = y 1 – y 2 ,
x 2 = y 1 + y 2 ,
x 3 = y 3 .
This transformation has a matrix A =  , that is [ x] = A[y] we get A(x,
x) = 2(y 1 – y 2)(y 1 + y 2) – 6(y 1 + y 2)y 3 + 2y 3 (y 1 – y 2) =
, that is [ x] = A[y] we get A(x,
x) = 2(y 1 – y 2)(y 1 + y 2) – 6(y 1 + y 2)y 3 + 2y 3 (y 1 – y 2) =
2 – 2
– 2 – 6y 1 y 3 – 6y 2 y 3 + 2y 3 y 1 – 2y 3 y 2 = 2
– 6y 1 y 3 – 6y 2 y 3 + 2y 3 y 1 – 2y 3 y 2 = 2 – 2
– 2 – 4y 1 y 3 – 8y 3 y 2 .
– 4y 1 y 3 – 8y 3 y 2 .
Since the coefficient at  is not equal to zero, we can select the square of one unknown, let it be y 1 . Let us select all terms containing y 1 .
is not equal to zero, we can select the square of one unknown, let it be y 1 . Let us select all terms containing y 1 .
A(x,
x) = 2( – 2y 1 y 3) – 2
– 2y 1 y 3) – 2 – 8y 3 y 2 = 2(
– 8y 3 y 2 = 2( – 2y 1 y 3 +
– 2y 1 y 3 +  ) – 2
) – 2 – 2
– 2 – 8y 3 y 2 = 2(y 1 – y 3) 2 – 2
– 8y 3 y 2 = 2(y 1 – y 3) 2 – 2 – 2
– 2 – 8y 3 y 2 .
– 8y 3 y 2 .
Let us perform a transformation whose matrix is equal to B.
z 1 = y 1 – y 3 , y 1 = z 1 + z 3 ,
z 2 = y 2 , y 2 = z 2 ,
z 3 = y 3 ; y 3 = z 3 .
B =  ,
[y] = B[z].
,
[y] = B[z].
We get A(x,
x) = 2 – 2
– 2 –
– – 8z 2 z 3. Let us select the terms containing z 2. We have A(x, x) = 2
– 8z 2 z 3. Let us select the terms containing z 2. We have A(x, x) = 2 – 2(
– 2( + 4z 2 z 3) – 2
+ 4z 2 z 3) – 2 = 2
= 2 – 2(
– 2( + 4z 2 z 3 + 4
+ 4z 2 z 3 + 4 ) +
+ 8
) +
+ 8 – 2
– 2 = 2
= 2 – 2(z 2 + 2z 3) 2 + 6
– 2(z 2 + 2z 3) 2 + 6 .
.
Performing a transformation with a matrix C:
t 1 = z 1 , z 1 = t 1 ,
t 2 = z 2 + 2z 3 , z 2 = t 2 – 2t 3 ,
t 3 = z 3 ; z 3 = t 3 .
C =  ,
[z] = C[t].
,
[z] = C[t].
Got: A(x,
x) = 2 – 2
– 2 + 6
+ 6 canonical form of a quadratic form, with [ x] = A[y],
[y] = B[z],
[z] = C[t], from here [ x] = ABC[t];
canonical form of a quadratic form, with [ x] = A[y],
[y] = B[z],
[z] = C[t], from here [ x] = ABC[t];
ABC = 

 =
=  . The conversion formulas are as follows
. The conversion formulas are as follows
x 1 = t 1 – t 2 + t 3 ,
x 2 = t 1 + t 2 – t 3 ,